



以前にも言いましたが、個人的には昨今の AI (人工知能とは絶対に言いません w )は、超高度なパターンマッチングくらいにしか思っていないのですが、最近、何気に話しかけた Gemini さんや Copilot さんがひらめきを与えてくれることが何度かあって、遅まきながら、使いパシリとはいえシステムエンジニアを名乗っている以上、もう少し何ができるか研究してもいいなぁ…と思い始めました。
…ということで、一応、うちにも、お絵描き専用となっていますが w、GeForce RTX 4060 というそこそこな GPU がありますので、ローカル LLM(large language Model) を試してみようと思い立ちました。
意外に LLM をインストールする、いわゆる Hello World 的ドキュメントは少なかったので、以下の PC Watch の記事を参考に、お気軽簡単 LM Studio で構築する方法をまとめてみました。
【特集】 無料で使える「LM Studio」でローカルLLM入門。導入から性能比較までそして、導入するのは、LLM 界のゲームチェンジャーと評される Alibaba が開発した中国製のオープンソースモデル、昨今、評判の Qwen 3.5 をターゲットに、まずは LM Studio のインストールから…
LM Studio のインストール
もちろん、上記の PC Watch の記事にあるように、公式 HP からインストーラーをダウンロードして、これを起動してインストールするのが正道ですが、Chocolatey や Winget ならもっと簡単。
Chocolatey なら
choco installl lmstudioWinget なら
winget install -e --id ElementLabs.LMStudioで超簡単 1 発インストール!ちなみに 2026 年 4 月 15 日現在、Winget の方が新しいバージョンがインストールされます。
LM Studio の設定
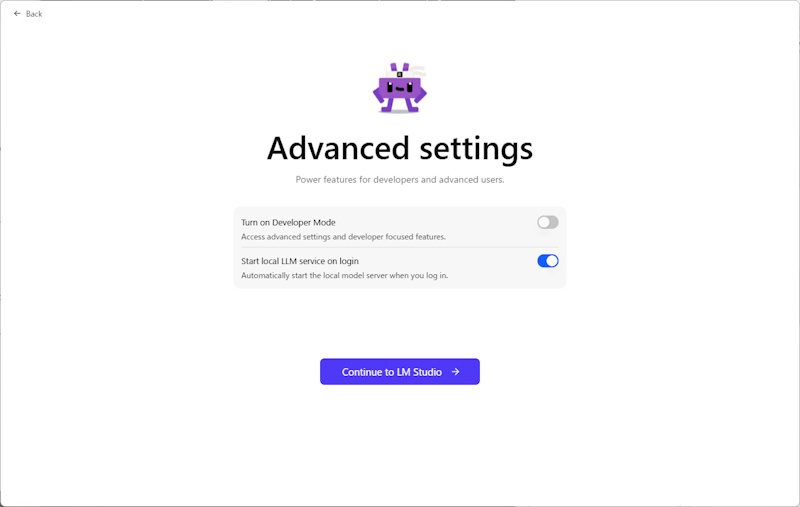
次に設定を聞かれますが、「Start local LLM service on login」(LLM サービスをログオン時に起動する)は、あとで LM Studio の設定からは自動起動を切ることができないので、切っておきましょう。
一応、ここで切らなくてもとスタートアップアプリから、自分で無効にすることはできます。
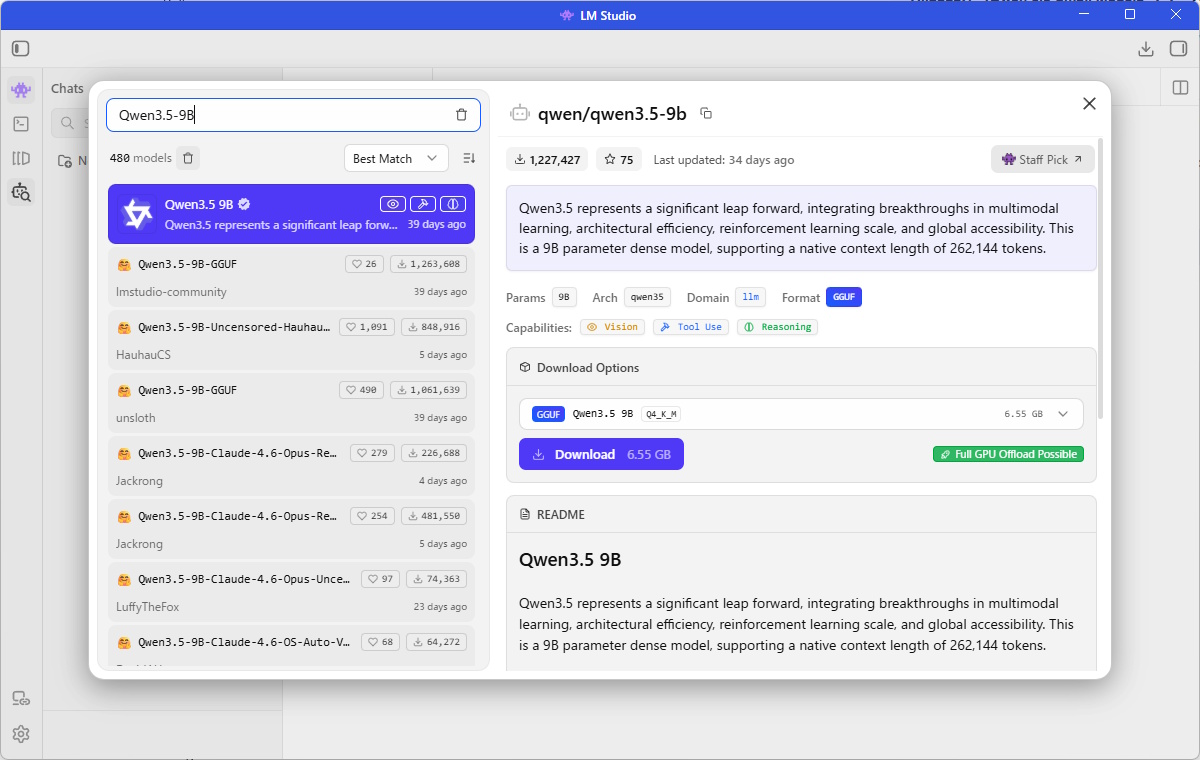
そうするとモデル検索のダイアログが上がってくるので、ここでダイアログ左上の検索ボックスに「Qwen3.5-9B」と入力して、一番上に出てくる「Qwen3.5 9B」を選択し、右側の詳細画面のダウンロードボタンを押すと、モデルのダウンロードが始まります。
6.5GB ありますので、環境にもよりますが、結構、時間がかかります。
モデルのダウンロードが終わって、モデルをロードするといよいよ Qwen さんとおしゃべりができるようになります!
Qwen さんとお話してみる
さて、当方では Intel Core i3-12100/DDR4 32GB/Geforce RTX 4060(8GB) と、AMD Ryzen 5 5600G/DDR4 16GB/GeForce RTX 3050(8GB) の双方の環境で試しましたが、Qwen3.5 9B をモデルとして、動作しました。
そもそもなぜこの 9B のモデルを選んだかというと、事前に Geforce RTX 4060 を動かすことを前提に Gemini さんに相談すると、これをお薦めされたから。パラメータ数とか量子化とか難しいことはさっぱりなので、疑うことなくこれに決めました w
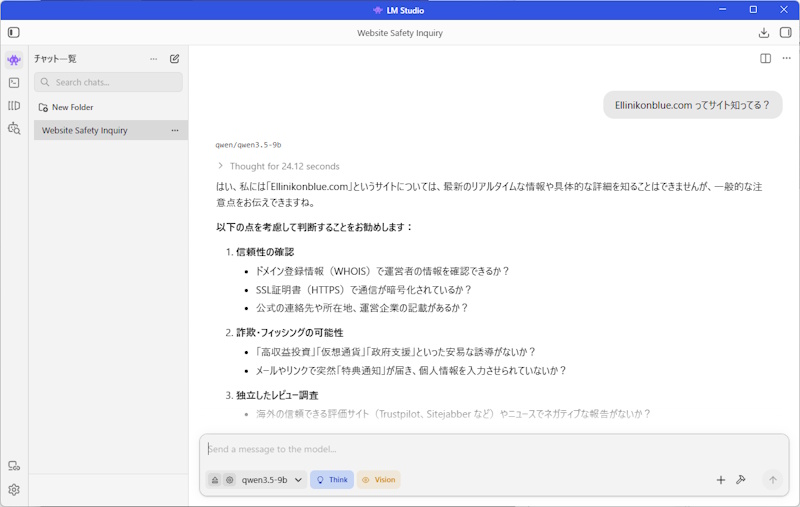
で、早速、「Ellinikonblue.com」ってサイト知ってる?って聞いてみると 30 秒弱ほど考えて、「知りません」と言われました orz
という小ネタはさておき w
考えてる時間はやはり、Gemini さんや Copilot さんなどの、ウェブサービスには及びませんが、このローカルにいる Qwen さんには、Gemini さんや Copilot さんにはできない内緒話を、無償でできるというのは、増えた話し相手としてはメリットを感じます。
Visual Studio Code でバイブコーディング…なんかしてみたい
と言うわけで、Qwen さんとおしゃべりができるようになったところで、これからどうお付き合いしていこうか考えていきたいと思います。
バイブコーディングなんかもできるかなんかも試したいなぁ…と活用方法を検討中です。
LM studio(ローカルLLM)をVScode上で利用してみた – Qiita